
 Ephesoft Transact and Insight to Feature Multi-Dimensional Extraction
Ephesoft Transact and Insight to Feature Multi-Dimensional Extraction
Executive Summary: At INNOVATE 2016, Ephesoft announced a new feature to be included in Transact and Insight: multi-dimensional extraction. This feature was described as using machine learning to improve extraction results from unstructured documents with minimal user intervention. While the description is very exciting, I was left wondering how the system accomplished this lofty goal.
Ephesoft was also proud to announce they had a received a US patent for the technology. I took it upon myself to read Ephesoft’s patent (US 9,384,264 B1) to find out what is going on behind the scenes. I’ll even share what I’ve learned so that no one else must repeat my experience.
The patent actually describes much more than just multi-dimensional extraction. It includes information regarding machine learning, system architecture to handle massive scale, and much more. However, I found the most insightful information to be the description of what “mult-dimensional extraction” truly means, and how Ephesoft is implementing the concept.
Multi-dimensional extraction is the process of using different techniques in combination to determine which text on a page is the true value that should be extracted for further analysis or processing. The patent refers to these techniques as dimensions. Each dimension analyzes the document in a different way, and their analyses are combined to determine the best candidate for extraction.
Several categories of dimensions are described within the patent. Value dimensions provide analysis of each piece of text individually to determine if a value is correct for extraction using information such as page location, page number, text format, font size, font style, and more. Anchor dimensions expand the analysis to include the words surrounding a particular value. These dimensions look at the neighboring words/phrases to determine if expected keywords are found, and if the value’s neighbors match any of the neighbors found during training. Finally, there are some use-case-specific dimensions described as well. For example, addresses and zip codes can be analyzed further by ensuring their validity from a list of known, valid addresses and zip codes.
Multi-dimensional extraction combines a wide variety of information to create a holistic approach to document-based extraction, which is strikingly similar to how humans perform the same task. Ephesoft has described a robust and flexible system for finding important information in unstructured text. I’m eager to see the performance of this feature in practice and expect to see improved extraction results from documents which previously proved difficult.
A much more in-depth discussion of the patent and multi-dimensional extraction can be found below.
Ephesoft Multi-Dimensional Extraction
One of the most exciting features in the upcoming Ephesoft Transact 4.1 release is “multi-dimensional extraction.” This was one of the highlights at the Ephesoft INNOVATE 2016 conference, but all I knew was that the new feature would improve extraction results, used machine learning, and was patented. While this was satisfactory for most attendees, I’m not one to just stop there.
I went ahead and read Ephesoft’s patent: US 9,384,264 B1. If you’re so inclined, you’re free to read it from the US Patent Office’s site. The patent describes not only this multi-dimensional extraction, but also provides information about potential architecture, user interface, machine learning, use cases, and more. Since I assume you’re a sane person who doesn’t want to read through the legalese in the patent itself, I’ll summarize what I learned about the internals of multi-dimensional classification in this write-up.
General Information About the Patent and This Post:
The information in this article is sourced directly from Ephesoft’s patent, along with some commentary based on my experience. Where possible, I’ve preserved the specific examples and numbers within the patent. These details provide a starting point, but it is possible that minor details may change when these concepts are implemented and tuned within Transact. Since I am not describing Ephesoft Transact or Ephesoft Universe directly, I’ll simply refer to an implementation of these concepts as “the system.”
Also, the terminology in the patent can be cumbersome. While it accomplishes its goal of being precise and consistent, meaning can be lost in the verbosity—I don’t think this is the least bit surprising for a patent. But to increase readability, I’ve taken the liberty of using slightly different or condensed terminology. The information is still quite dense. So get a cup of coffee, take a deep breath, and let’s dive into the next generation of document capture.
Document-Based Extraction:
Document-based extraction is the process of extracting relevant information from an unstructured document. The process begins with a user providing sample documents. Then the user identifies which values within those samples should be extracted. When the system encounters future documents of the same type, it will attempt to extract those same values that the user-defined. This extracted information can then be used to drive business processes or be stored for future analysis.
Let’s consider a more concrete example: extracting information from a deed of trust document commonly found in mortgages. The user would begin training the system by providing a sample deed of trust. The user may then select which pieces of information they would like to extract from this type of document. In our example, the user is interested in the Mortgage Identification Number (MIN). The user would select the MIN from the sample document, and this
tells the system that it should attempt to find the MIN when it sees more deed of trust documents in the future. In this example, the exact, user-selected MIN from the sample document is called the predefined value. The predefined value is an extraction example from the user which the system can store and refer to later. After this training, the MIN is now a sought value, or a value which the system should attempt to extract the next time it sees a deed of trust.
In general, the extraction process seeks to identify all of the user-defined sought values from a document. The system begins by identifying the words and phrases within a document using OCR. These pieces of text are the contender values (or contenders) since any one of them may be the sought-after piece of data which should be extracted. The system must then decide which of these contenders is most likely to be the correct value to extract.
Multi-Dimensional Extraction:
Multi-dimensional extraction is the process of using different techniques in combination to determine which contender is the true sought value. The patent refers to these techniques as dimensions. Each dimension analyzes the document in a different way, and produces a confidence score between 0 and 1. The confidence score represents the likelihood that a particular contender is the sought value. The larger the confidence score, the more likely that dimension believes the contender value to be the sought value.
By combining the confidence scores across different dimensions, the system can determine which contender is the best. The confidence scores from the different dimensions are merged together into a weighted average, producing a single confidence score for each contender value. The contender with the highest, overall confidence score is most likely to be the sought value for that document. At a high level, this is how the system determines which word or phrase is found to be the relevant piece of data which should be extracted.
Multi-dimensional extraction is a holistic approach which closely resembles how humans intuitively perform the same extraction task. When someone is searching for a value within a document, they quickly use a wide variety of information to narrow their search. The user may already expect the value to be in a certain location on the page, be in a particular format, have a distinct font type, be next to a keyword, etc. But humans are also flexible with these criteria. If the value has most of the expected attributes, but not all, they can still determine which value is the one they really want. Ephesoft’s multi-dimensional extraction brings this same behavior to an automated system. The system combines multiple data points, considers which are the most important for this particular value based on previous training, and intelligently selects the correct text to extract from the document.
The following takes a deeper dive into how this actually works and the individual dimensions described in the patent.
Extraction Dimensions:
Identifying Blocks:
I mentioned previously that the system finds words or phrases within a document. Even though I glossed over this point, it merits further discussion. While OCR provides the raw characters and word boundaries, that’s not quite enough. The sought value may span across multiple words or even wrap around multiple lines. The system handles this scenario by grouping the OCR results into blocks. A block is one or more words which can be grouped together to create a logical unit. The patent provides Fig 1 to illustrate this concept.
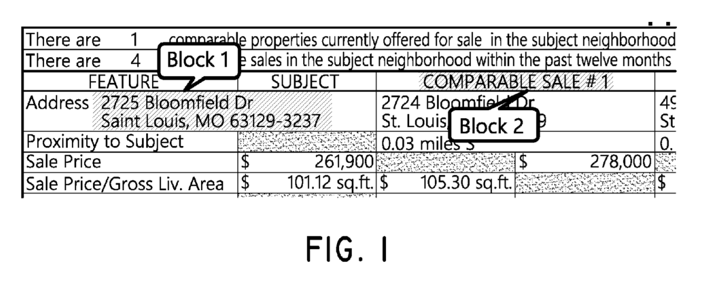
In Fig 1, we can see two blocks have been identified. Block 1 is an address within the form while Block 2 is part of the form’s text.
To identify blocks, the system uses information such as font type, font size, spacing between words, and surrounding whitespace to determine which groupings of texts belong to the same logic unit (a block). Again, this is very reminiscent of how the human eye naturally distinguishes separate blocks of text.
These blocks are clearly better than having just the words and characters from the OCR process, but now we need to identify which of these is actually the value we want. If we look to Fig 1 as an example, the system must understand that we want the address in Block 1, not the form text in Block 2. To understand how the system makes that decision, we’ll look at the individual dimensions which the system uses to determine which block is the correct value to extract.
Value Dimensions:
Let’s start by analyzing the blocks themselves. Recall that any block on the page is a contender value, and the system must determine which of these contenders is actually the sought value. The value dimensions category is a group of dimensions which use features of the contenders (such as their format or contents) to determine if the contender may be the sought value. These dimensions seek to answer the question: does the contender look right? These dimensions could be utilized to reduce the search space of contenders, since some could be quickly eliminated if they don’t meet certain criteria. That is to say, if the contender looks obviously wrong (since it’s perhaps in the wrong location or format), then the system may save time by not considering it any further.
Value Imprecision Dimension:
This dimension compares the contender value to the expected format and returns a confidence score representing how closely the dimension matches the expected format. The expected format may be a regular expression, or a more generic type such as Integer, Number, Date, Dollar Amount, etc.
It’s important to note that this comparison is not a strict choice between matching the expected format or not matching the format—this dimension has much-needed flexibility. Recall that the text being analyzed is coming from an OCR process. Any OCR process is bound to have some level of error, with characters being misidentified.
For example, if the expected value format is an integer, then the correct format for a contender is only digits. If a document contained the value “69010” but the OCR process incorrectly identified the block as “690J0,” then this contender does not strictly match the expected format. This dimension would still assign a relatively high confidence score to this contender, since it is a close match. In the patent, Ephesoft cites a 70% character match as the threshold for near matches.
This flexibility does bring complications as well. If the system allows for the extraction of values which don’t fit the expected format, it may be difficult to work with those values later. Consider the scenario of extracting dollar amounts from an invoice to calculate a sum. The system may allow for OCR mistakes and some of the dollar amounts we extract could contain letters in place of digits. We can no longer simply add the extracted values together and may have to manually review those values, or define a process to convert those letters into the correct digits. I still believe this flexibility is an improvement, but there are no free lunches.
Type Hierarchy Dimension:
Another dimension also uses the contender’s format for comparison against known formats. However, the type hierarchy dimension relates these formats into a relational structure, allowing some formats to be more closely related than others. This hierarchy of data types can be defined during training. If a contender has the same data type as the sought value, it will receive the highest confidence score. If a contender does not have the same data type as the sought value, but matches a data type which is hierarchically close to the sought value, it will receive a lower, but still relatively high confidence score.
The example in the patent provides the following hierarchy in Fig 4:
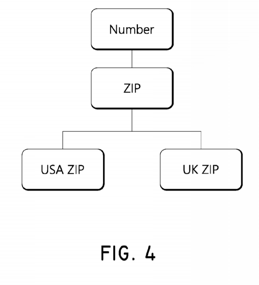
Let’s consider the extraction of US zip codes. The best contender would match the data types of a “Number,” a “ZIP,” and a “USA ZIP.” This contender would receive a very high confidence score from this dimension. If another contender matches the data type of a “UK ZIP,” then it will have a lesser, but still relatively high confidence score since these data types are closely related in the hierarchy.
This provides the system with more intuition. A human would understand that if a US zip code isn’t available, then a UK zip code is probably the next best value to extract. Using the previous example, this dimensions allows the system to prioritize a contender in a different format of “ZIP” over a contender which isn’t a “Number” at all.
Value Quantization Dimension:
This dimension provides a confidence score based on informational aspects outside of text characters. You may be thinking, “Wait, the system is doing text analysis, but not looking at the characters?” It’s actually not too crazy and fits how humans perform this task as well. Although we may be reading the characters, we’re also recognizing a lot more information such as font type, font size, date or number format, upper or lowercase, and much more. This dimension also utilizes those features when analyzing each of the contenders. The more features a contender has that match the sought value’s features, the higher the confidence score.
For example, if the user identified a predefined value as “123-45-6789” then a contender value of “987-65-4321” will receive a higher confidence score than a contender value of “987.54.4321” since it matches the format more precisely. Similarly, if the user’s predefined value is “ACME INC.,” then a contender value of “WIDGETS CO.” would get a higher confidence score than “dingbats ltd.”
By analyzing additional information, this dimension allows the system to recognize the more subtle identifiers of relevant values.
Page Zone Dimension:
The page zone dimension provides a confidence score based on where the contender value is located on the page, compared to the location where the predefined value existed in the sample document during training. For example, if the predefined value was located in the top left of the sample document, a contender in the top left of its document will be assigned a higher confidence score.
The patent provides Table 1 as a diagram of how a page is split into nine zones:
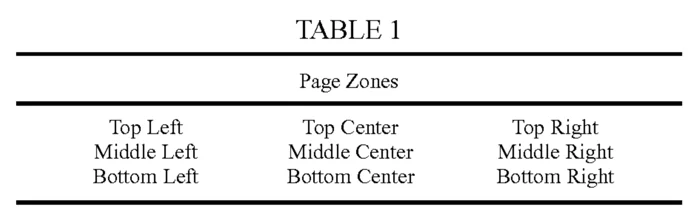
This dimension is pretty straightforward and the functionality is available in previous Ephesoft Enterprise versions. Although this idea seems obvious to someone searching for values manually, this dimension captures information that may have gone unused.
Page Number Dimension:
Similar to the page zone dimension, the page number dimension determines its confidence score of a contender value by comparing which page of a document the contender was found and on which page within the sample document the user identified the predefined value during training. For example, if the predefined value was identified by the user on the first page of the sample document, contender values identified on the first page will receive higher confidence scores.
Although the patent doesn’t directly mention it, this dimension highlights that the system must correctly classify the documents from each other as well. If the input to the system is a series of pages, the system must identify separate documents within those pages. For example, consider the input to the system is two deed of trust documents, each 10 pages long. The system must separate the documents appropriately to understand that both page #1 and page #11 are “first pages” of different documents.
Ephesoft already provides mechanisms for document classification based on text content and document appearance. There are some indicators that similar multi-dimensional analysis will be used for document classification as well, but this is not addressed in the patent.
Fixed Value Location:
The fixed value location dimension allows the user to specify a coordinate box for values during training. Any contenders within this rectangular area will be given a higher confidence score. This can be especially useful for structured documents which have dedicated value areas. Many structured forms have specific sections that are populated with values, this dimension ensures that structure is not being overlooked.
Anchor Dimensions:
I think it’s about time to get a refill on that coffee you got earlier. We’re about to go deeper down the rabbit hole. The next category of dimensions not only analyze the contender values, but the surrounding blocks as well. These are the anchor dimensions. The following section will describe in detail how these neighboring blocks are found and how they are analyzed to provide additional confidence scores to a contender value.
Finding Anchors:
An anchor is a block which has a spatial relationship to a contender value. That is, an anchor’s relationship to a contender value could be described using words like: above, below, near, far, left, right, etc. To find anchors, the system must first identify all the blocks on the page (as discussed in the “Identifying Blocks” section). The blocks can then be related to each other based on proximity. This creates a bidirected graph of blocks related to each other. The patent provides Fig 2 as an illustration:
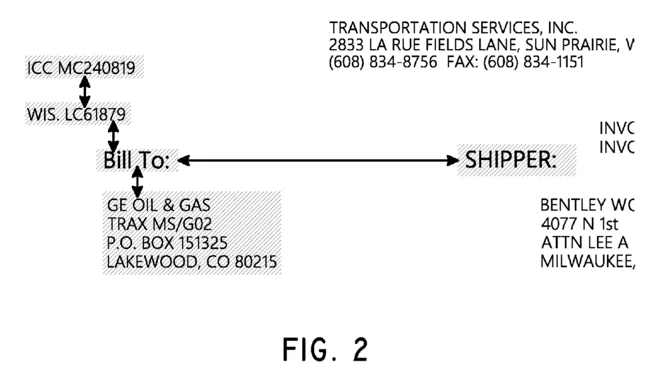
For any selected block in the graph, the other blocks can be used as anchors. The anchors are assigned a weight (a score from 0 to 1) based on their location relative to the selected block.
The patent provides Fig 3 to help describe the process of identifying anchors and assign them weights relative to a selected block. I’ve used cutting-edge technology (MS Paint) to convert this simple black and white image into a more descriptive, colorful animation. The animation demonstrates how different blocks are assigned different weights according to their location. All of the numbered blocks around the “Value Block” are the anchors, and the red numeric values are their weights.
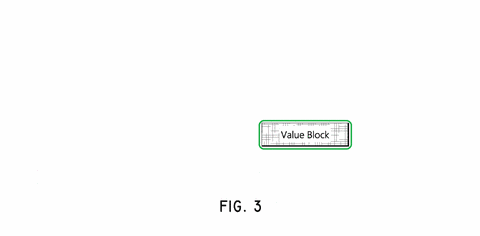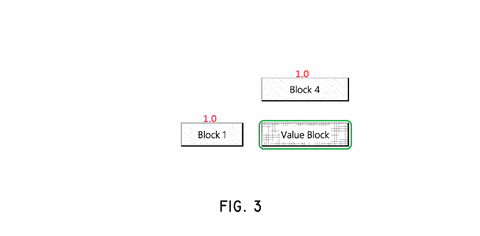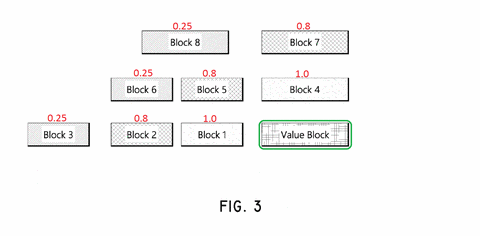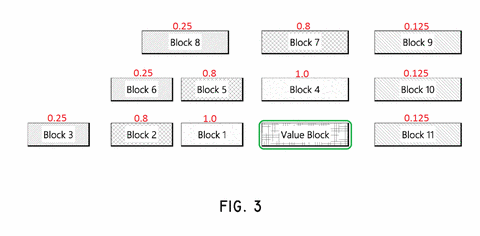
The anchors immediately above and to the left of the selected block have the highest weight. This is because in a left-to-right written language, these blocks are most likely to be relevant to the selected block. This continues outward, with the anchors to the right of the selected block being less relevant, but still non-zero.
During the training of the system, the user provides a predefined value (a block containing the information the user wishes to extract). The system identifies the anchors for that selected block, and saves the anchors along with their weights relative to the predefined value. This set of anchors and weights is stored as the training anchors.
Anchor Matching Dimension:
This dimension compares the anchors around contender values to the training anchors which were identified around the user-provided, predefined value. For each contender value in a document, the system identifies its anchors using the process described in the previous section. This creates a set of anchors and weights for each contender. This set is referred to as the testing anchors for that contender.
Recall that a dimension must provide a single confidence score for each contender, representing how likely that contender is to be the sought value. The anchor matching dimension calculates its confidence score for each contender using the following algorithm. The patent provides a mathematical formula for how the confidence score is calculated. But math is scary and I wouldn’t dare subject you to that. Instead, I’ve rewritten the formula into pseudo-code (although I’m sure some people find that equally scary). If you’re not interested in that level of detail, just skip over it.
# The minimum number of anchors needed to create a straightforward average
anchor_threshold = 5
# The set of anchors and their confidence weights identified in the training phase
training_anchors = load_training_blocks()
# The set of anchors and their confidence weights identified for some contender value
# in the testing phase
testing_anchors = get_anchor_blocks(some_contender_value)
# If a testing anchor isn't in the set of training anchors, give it 0 weight
# (essentially disregarding it)
for testing_anchor in testing_anchors:
if testing_anchor not in training_anchors:
testing_anchor.confidence = 0.0
# When handling very few anchors, the average is weighted differently to avoid very
# few anchors resulting in very high confidences.
divisor = 0.0
# Check if the number of anchors is greater than the threshold
if testing_anchors.size > anchor_threshold:
divisor = testing_anchors.size
else:
adjusted_size = testing_anchors.size - .5 * (anchor_threshold - testing_anchors.size)
divisor = min(adjusted_size, training_anchors.size)
# This will be our final, single confidence score for the contender value.
confidence_score = 0.0
# Compute our "average"
for testing_anchor in testing_anchors:
training_anchor = training_anchors.get(testing_anchor)
min_confidence = min(training_anchor.confidence, testing_anchor.confidence)
max_confidence = max(training_anchor.confidence, testing_anchor.confidence)
confidence_score += (min_confidence / max_confidence) / divisor
return confidence_score
Essentially, this algorithm computes a type of average to get the final confidence score. This average compares the testing anchors around each contender value to training anchors identified in the training phase. The more matches the system is able to find between the testing anchors and the training anchors, the higher the confidence score. There is also some special handling around the case when the system identified very few anchors in the testing anchors.
Comparing Anchors:
It’s important to note that if an anchor in the testing anchors set does not match any anchor within the training anchors set, then it is essentially disregarded from the comparison. This means that if none of the testing anchors match any of the training anchors, then the final confidence score for that contender will be 0.0 in this dimension.
But determining if two anchors match is not a literal, one-to-one character comparison. The system accounts for imprecise OCR results by allowing some characters to be different between the blocks, and still considering them to be a match. The patent specifically cites considering a 70% character equivalence between two anchors to be a match. This is very similar to the value imprecision dimension which allows for fuzzy matching as well.
In addition to allowing some character differences, the system allow uses the root-stem of words to find matches between anchors. For example, anchors with the text “Borrower Name,” “Name of Borrower,” and “Borrowing Party” may be considered matches since they all contain the root-stem “borrow.” This allows for greater flexibility than can be achieved with simple, fuzzy character matching.
All of these components combine to create a single dimension: the anchor matching dimension. It is only one method of generating a confidence score indicating that a word or phrase may be the value the system wants to extract.
Anchor Position Dimension:
The anchor position dimension uses positions of the anchors relative to each other to generate a confidence score. Far fewer details are given regarding this dimension. In the example that is provided, the patent describes how if an anchor in the training set contains the text “Borrowing Name,” then “the system learns that the word ‘Borrowing’ appears before the word ‘Name.'”
Although very little text is given to this dimension within the patent, it highlights an important feature demonstrating that the system is not only identifying blocks of text, but also inspecting their contents in a meaningful way. I wish I had more information to provide on this dimension, but any further discussion would devolve into speculation.
Predefined Keywords Dimension:
This dimension boosts the confidence of a contender if its anchors contain certain words. During training the user can associate one or more predefined keywords with the predefined value. The anchors for any contender values are then checked to determine if they contain any of these keywords—increasing the confidence score if they are found.
For example, consider a user training the system to find Social Security Numbers. The user would identify the predefined value within the sample document, then provide predefined keywords such as “SSN” and “Social Security number.” This would boost the confidence score of contender values which are near these terms in future documents processed by the system.
This is similar to the existing key-value extraction functionality within Ephesoft, but it seems to lift the more rigid coordinate restrictions.
Use-Case-Specific Dimensions:
The final category of dimensions are only utilized for certain types of values. Specifically, these dimensions improve extraction results for ZIP codes, coordinates, and addresses. I expect that as the system grows, more use use-case-specific dimensions will be identified and integrated into the system.
Zip Code Location:
US addresses typically follow the same format: <street number> <street name> <city>, <state> <zip code>. The zip code location dimension uses the fact that a zip code typically follows the city and state names. If a contender value is found following a city name and/or state name, that contender will receive a high confidence score. The patent provides Fig 5 to illustrate this idea:

The system will assign a higher confidence to the contender value “92653” than the contender value “23041” due to the former’s relative position to the city name (“Laguna Hills”) and state name (“CA”). Even though these are both five-digit values, this dimension boosts the overall confidence score of the contender which is truly a zip code.
Zip Code Dictionary:
Another enhancement for zip code extraction comes from the zip code dictionary dimension. As the name suggests, the system can compare a contender value against a dictionary of known, valid zip codes for a given country. If the contender matches a valid zip code, it receives a higher confidence score. Interestingly, the patent expressly acknowledges that this dictionary may be remote, which means this comparison could happen outside the system itself.
Geolocation:
The geolocation dimension takes the concept of the zip code dictionary a step further. This dimension compares whole addresses or coordinates against known, valid values. If a contender contains an address or coordinate value which is determined to be valid, it receives a
higher confidence score. Similar to the zip code dictionary dimension, this validation may happen remotely. The list of valid addresses may exist outside of the system (e.g. a post office database), and be referenced as necessary.
Conclusion
The patent’s discussion of multi-dimensional extraction concludes with an acknowledgement that the system may use some or all of these dimensions when extracting value. Additionally, the dimensions may be weighted differently, such that some dimensions factor into the overall confidence score of a contender more than others.
I very much like the approach of combining the results of different, discrete analyses. This encourages a flexible system where further dimensions could be added later as they are identified. Each of the dimensions could also be tuned such that the most effective ones are regarded highly within the system, and the less effective dimensions factor into the final result less.
While it still waits to be seen in practice, the potential is exciting. The ideas discussed in this patent will result in a system which extracts information much like a human. Wherever possible, information will be utilized to the fullest extent and not simply thrown away. I see this as a leap forward for the document capture industry.
To learn more about how we can create customized solutions for you, or for a personalized demo of how this functionality works, contact us today.
 Jake Karnes is an ECM Consultant at Zia Consulting. He extends and integrates Ephesoft and Alfresco to create complete content solutions. In addition to client integrations, Jake has helped create Zia stand-alone solutions such as mobile applications, mortgage automation, and analytic tools. He’s always eager to discuss software to the finest details, you can find Jake on LinkedIn.
Jake Karnes is an ECM Consultant at Zia Consulting. He extends and integrates Ephesoft and Alfresco to create complete content solutions. In addition to client integrations, Jake has helped create Zia stand-alone solutions such as mobile applications, mortgage automation, and analytic tools. He’s always eager to discuss software to the finest details, you can find Jake on LinkedIn.








